This repo is the bare-metal Kria KV260 implementation (RTL + driver + application) of the pccx v002 NPU architecture. It exists to close the loop between the pccx architecture specification and a working Gemma 3N E4B decoder on a real FPGA.
The design rationale, ISA, memory map, and model-mapping notes live on the pccx documentation site. This repo implements what that site specifies — read the spec first, then come back here for the RTL.
→ pccx v002 — Architecture & ISA spec · Gemma 3N E4B on pccx v002 · 한국어 문서
Related repos: pccx (spec) · llm-lite (x64 golden reference)
| Layer | Lives in | Authoritative source |
|---|---|---|
| Architecture / ISA / driver spec | pccx/docs/v002/ |
pccx v002 docs |
| Target-model pipeline (Gemma 3N E4B) | pccx/docs/v002/Models/ |
Models section |
| RTL (SystemVerilog) | this repo — hw/rtl/ |
— |
| Bare-metal driver (C/C++) | this repo — sw/driver/ |
API spec: Drivers/api |
| Application | this repo — sw/gemma3NE4B/ |
— |
If you want to read about how the accelerator works, head to the pccx v002 docs — that's the canonical source for every architectural decision in this repo. If you want to read the RTL or synthesize the bitstream, stay here.
Click the diagram for the annotated top-level page on the pccx site.
Three heterogeneous cores around a centralized L2 URAM cache:
| Core | Shape | What it runs |
|---|---|---|
| Systolic Array (GEMM) | 32 × 16 × 2 | Prefill — Q · Kᵀ across the full context, FFN in prefill |
| GEMV Core | 32 × 1 × 4 | Decode — every projection in the autoregressive step |
| SFU (CVO) | 32 × 1 × 4 | Softmax · GELU · RMSNorm · RoPE · sin/cos · reduce · scale · recip |
- Clock domains: AXI 250 MHz ↔ core 400 MHz, crossed by async CDC FIFOs.
- Weight path: HP0/1 = GEMM weights, HP2/3 = GEMV weights, 128-bit/clk each.
- Activation path: host DDR4 → ACP DMA → L2 URAM (1.75 MB, true dual port).
- Direct-connect FIFO: GEMV → SFU, so softmax runs without an L2 round-trip.
Full rationale and numbers: Top-Level → · Design rationale →
Weight-stationary 2D systolic layout. Activations broadcast along columns, partial sums propagate vertically into the result accumulator. Used only during prefill; idle during decode.
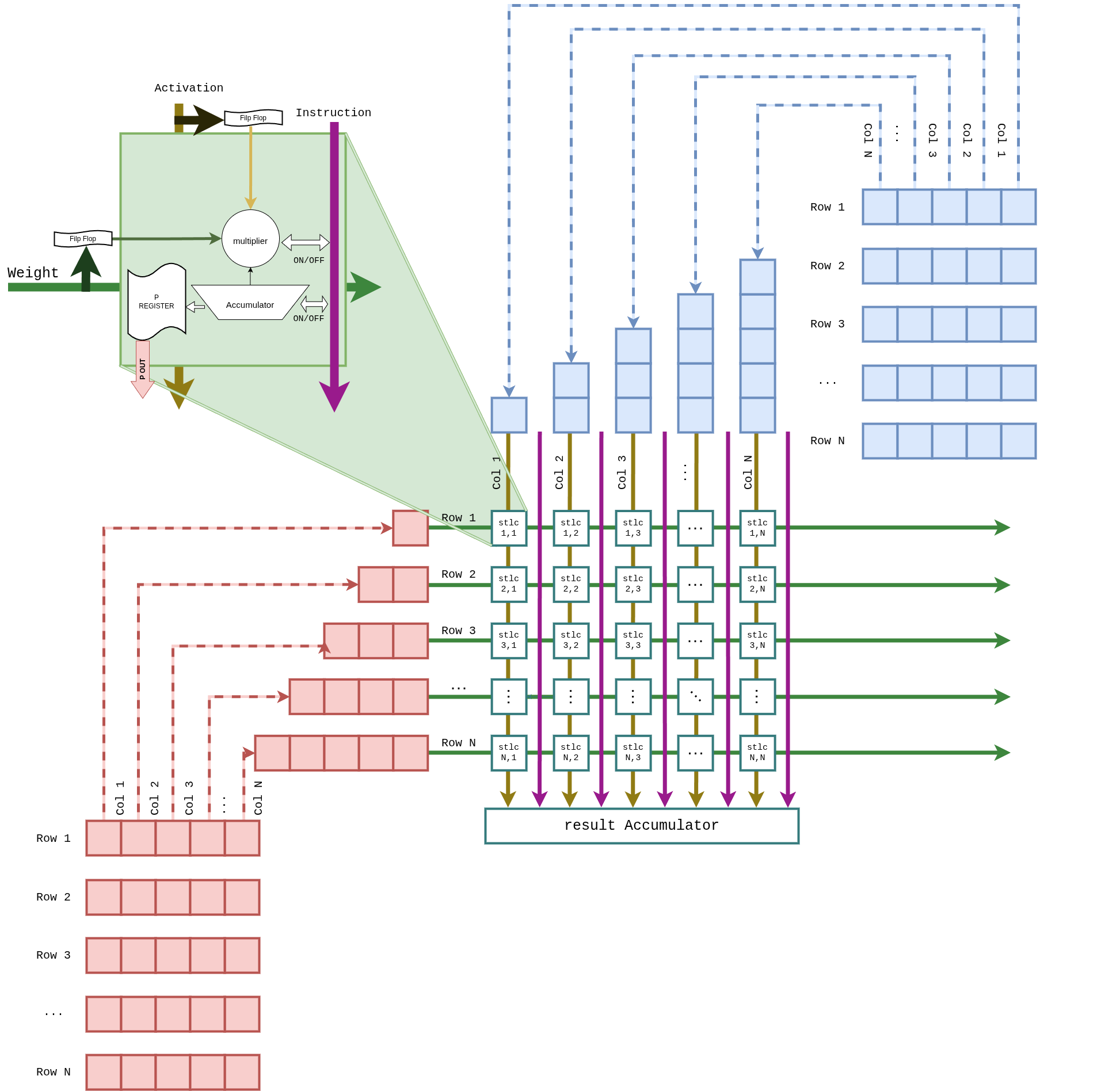
Inside each PE — a DSP48E2 wrapped with input flip-flops on both Activation and Weight ports, and an accumulator with a P-register output:
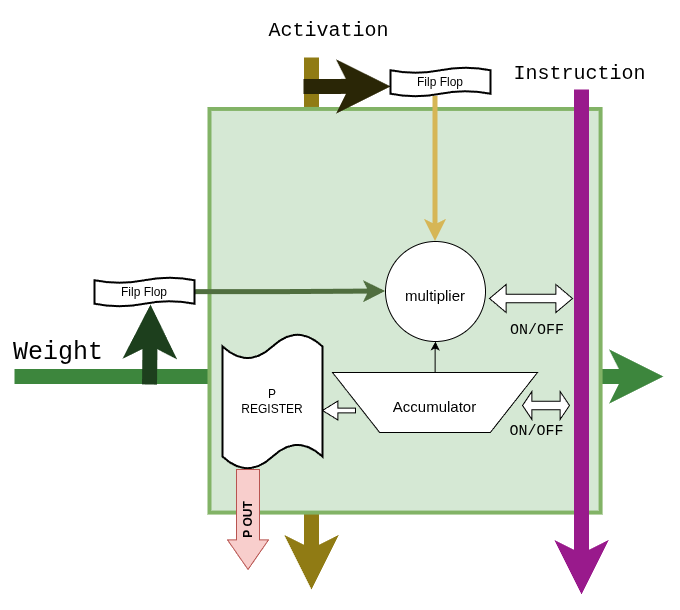
Details: GEMM core → · GEMM dataflow →
Four parallel GEMV lanes, each an 8-wide DSP pipeline fed by an Activation broadcast and a Weight row. Outputs feed a reduction tree that collapses partial products into the final vector entry register. The primary compute path during autoregressive decode.
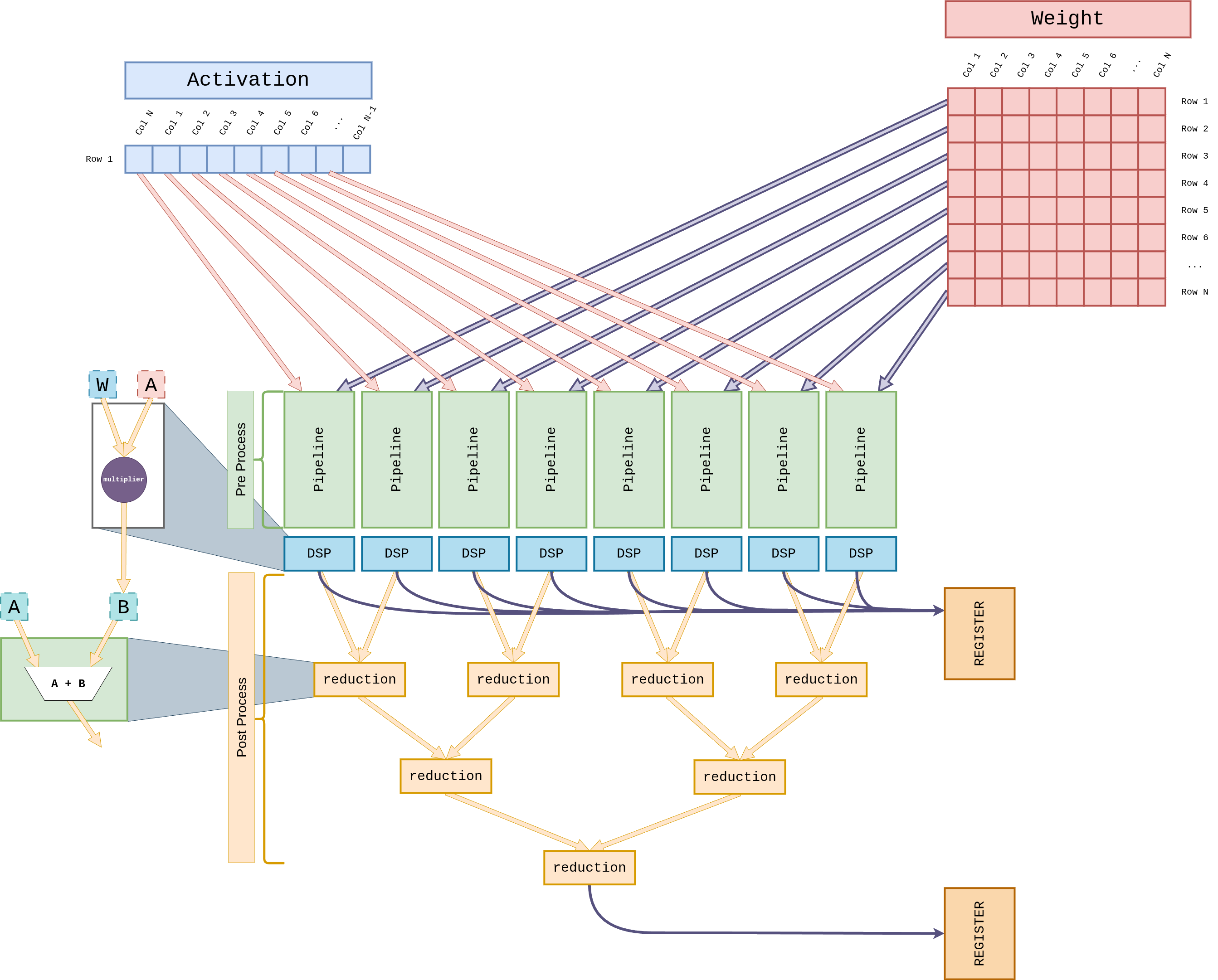
Per-cycle operand shapes — a 1×N activation row multiplied against an N×N weight tile:
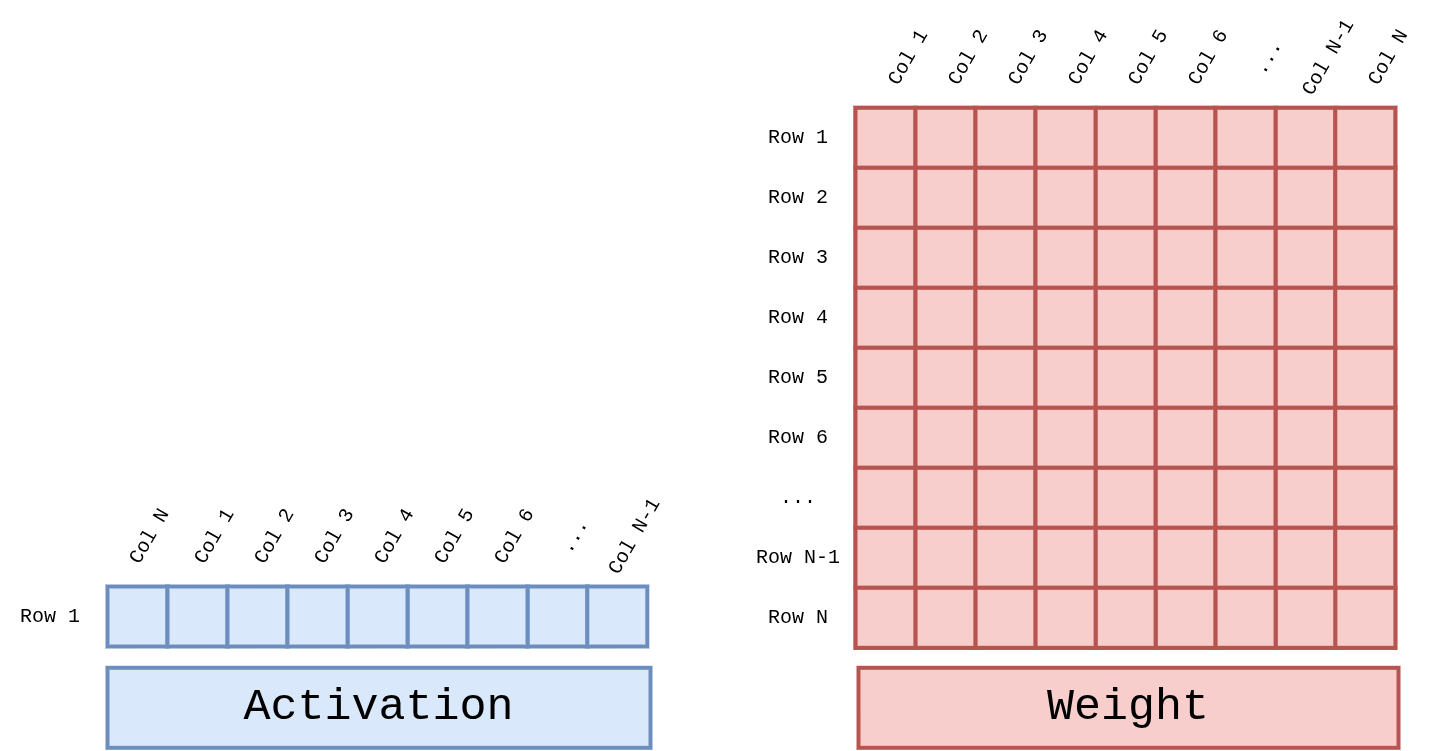
Details: GEMV core → · GEMV dataflow →
The DSP48E2 has a single 27×18 multiplier, not two. pccx v002 bit-packs two INT4 weights into port A alongside a single INT8 activation on port B, so each DSP emits two MACs per cycle into the 48-bit accumulator with a 19-bit guard band between the two channels.
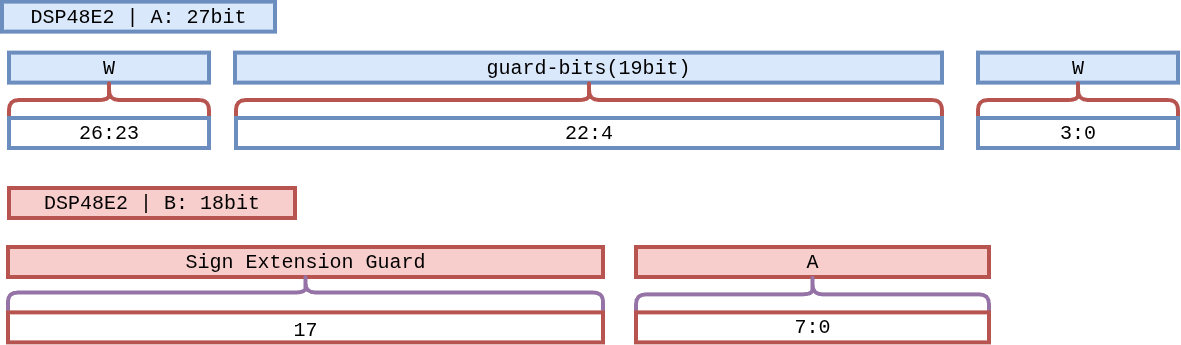
After accumulation, a sign-recovery step restores the upper channel when the lower channel borrowed a carry:

- Maximum accumulations before draining the ACCM: 2^10 ≈ 1024 per channel (guard-band limited).
- For K > 1024 (e.g. Gemma 3N's FFN with K = 16384), the Global Scheduler drains the ACCM every 1024 cycles into a LUT-based adder tree and merges the partial sums.
- Peak: 2048 MAC × 400 MHz ≈ 819 GMAC/s across the two systolic arrays.
Details: DSP48E2 W4A8 bit-packing →
The target model (Google Gemma 3N E4B) has several deviations from a textbook decoder that the scheduler has to honor. The short list:
| Feature | Effect |
|---|---|
| AltUp 4 residual streams | Four copies of xs live in L2; main stream xs[0] stays clean, shadow streams xs[1..3] receive depth-dependent updates. |
| Alternating RoPE θ (5-layer cycle) | θ = 10 000 (local) or 1 000 000 (global), preloaded per-layer via MEMSET. |
| No attention scaling, no softcap | Softmax sequence drops from 4 CVO instructions to 3. |
| LAuReL parallel branch | Two tiny GEMVs (D × 64, 64 × D) + a CVO_SCALE by 1/sqrt(2). |
| PLE shadow-stream injection | Per-Layer Embedding only touches xs[1..3] at the end of each layer; the main stream is untouched. |
| FFN Gaussian Top-K sparsity (L0–9) | Replaces a sort with Mean + 1.645·Std; ~95 % of gate_raw becomes zero and W_down skips masked rows. |
| Cross-layer KV sharing | Only layers 0–19 own their KV cache; layers 20–34 reuse layer 18 (local) or 19 (global). Cache shape is [20, L, 512], not [35, L, 512]. |
End-to-end decode flow, per-cycle overlap strategy, instruction-level mapping, memory layout, and the performance budget all live in the pccx Models section:
- Gemma 3N overview
- Full operator pipeline (embedding → sampling)
- Attention & RoPE constraints
- PLE & LAuReL routing rules
- FFN Gaussian Top-K sparsity
- Execution & scheduling on pccx v002
Five opcodes, 64 bits each: [63:60] opcode + [59:0] body.
| Opcode | Mnemonic | Use |
|---|---|---|
4'h0 |
OP_GEMV |
Vector × Matrix — decode projections |
4'h1 |
OP_GEMM |
Matrix × Matrix — prefill Q·Kᵀ, A·V across full sequence |
4'h2 |
OP_MEMCPY |
Host DDR4 ↔ L2 DMA (ACP) |
4'h3 |
OP_MEMSET |
Write shape / size / scale constants to the Constant Cache |
4'h4 |
OP_CVO |
Element-wise non-linear (exp, sqrt, GELU, sin, cos, reduce_sum, scale, recip) |
Spec: Per-instruction encoding → · Dataflow per opcode →
The pipeline is fully decoupled: the front-end decodes and enqueues into per-engine FIFOs, and each compute engine fires independently once its local dependencies (weight stream, fmap ready) are satisfied. A stall in one engine never halts another.
GEMV flags.findemax=1 ; Q · Kᵀ, track e_max
CVO CVO_EXP flags.sub_emax=1 ; exp(score - e_max)
CVO CVO_REDUCE_SUM ; Σ exp → scalar
CVO CVO_SCALE flags.recip_scale=1 ; divide each exp by the sum
KV bandwidth (not FLOPs) is what pins down L on KV260. At 32 K context
the cumulative cache would hit ~1.31 GB, and DDR4's ~10 GB/s puts
floor-to-floor read time above 130 ms per token. Three mitigations,
enforced at RTL / memory controller / driver level:
- KV quantization — DRAM format is INT8 (default) or INT4. 2–4× bandwidth and capacity savings, aligned with the W4A8 compute path.
- Attention-sink + local-window eviction — the driver retains only the first few tokens and a sliding recent window; middle tokens are evicted on a schedule, combined with Google Turbo-Quant-style requantization.
- Hard cap — the KV ring-buffer ceiling is set at init
(
max_tokens = 8192). Wrap-around overwrites the oldest entries. This bounds both OOM risk and worst-case memory traffic.
Details: KV cache strategy →
This repository hosts the RTL for both active tracks. As of 2026-04-20:
| Track | Target model | Goal | Horizon | Shared RTL assets |
|---|---|---|---|---|
v002 Extended (this repo, main) |
Gemma 3N E4B | 20 tok/s measured | Week 1–49 | sparse weight fetcher (Phase G), EAGLE draft/verify dispatch (Phase H+), SSD scheduler (Phase I), tree mask generator (Phase J) |
| v003 (future branch) | Gemma 4 E4B | 12–15 tok/s | Week 16–52 (parallel) | reuses v002 Phase G/H/I/J modules with hidden/layer/KV-head re-parameterization |
- v002 freeze → snapshotted into
pccx/codes/v002/via the pccx version-cutover workflow (tools/freeze_active.sh). - v003 lives on a later branch of this same repo; the pccx docs site
will fork its own
v003/docs tree at the same time.
Full phase-by-phase plan, decision points, compute budget, and Year 2 Auto-Porting Pipeline α vision:
→ Roadmap (EN) · 한국어
| Block | Status |
|---|---|
| Custom VLIW ISA | Spec complete |
| VLIW frontend + decoder | RTL complete |
| Global Scheduler | RTL complete |
| Systolic Array (Matrix Core, v001 32×32) | RTL complete |
| GEMV pipeline (Vector Core, 4 lanes) | RTL complete |
| CVO SFU + CORDIC | RTL complete |
| FMap preprocessing (BF16 → fixed-pt) | RTL complete |
| L2 URAM cache + ACP DMA | RTL complete |
| CVO ↔ L2 stream bridge | RTL complete |
| NPU top-level wiring | RTL complete |
| Python golden model | Verified |
| pccx v002 re-parameterization (1 DSP = 2 MAC) | In progress |
| uXC driver (AXI-Lite HAL) | Skeleton |
| Gemma 3N E4B application (submodule) | Skeleton |
| Simulation / trace-driven verification | Not started |
| Vivado synthesis + timing closure | Not started |
The current
hw/rtl/tree reflects the v001 parameterization (W4A16 / 32×32 array / 1 DSP = 1 MAC). Re-parameterization to the v002 target (W4A8 / 32×16 ×2 / 1 DSP = 2 MAC) is the current in-flight task. See the design rationale for the 3.125× theoretical speedup.
hw/
rtl/
NPU_top.sv ← top-level wiring
NPU_Controller/ ← VLIW frontend, decoder, Global Scheduler
MAT_CORE/ ← Systolic array, normalizer, packer
VEC_CORE/ ← GEMV pipeline (4 μV-Core lanes)
CVO_CORE/ ← CVO SFU + CORDIC unit
PREPROCESS/ ← BF16 → fixed-pt pipeline, fmap cache
MEM_control/ ← L2 cache, DMA dispatcher, CVO bridge, HP buffer
Constants/ ← `define macros + SystemVerilog packages (A → D)
Library/ ← BF16 math pkg, algorithms pkg, QUEUE
sw/
driver/ ← AXI-Lite MMIO HAL + inference API (skeleton)
gemma3NE4B/ ← Gemma 3N E4B application (submodule)
docs/ ← Redirect stub only — full docs live on pccx
docs/ in this repo is intentionally a redirect stub. All
architectural and model documentation now lives in the pccx repo /
GitHub Pages site.
Apache 2.0 — same as pccx. This protects the architecture from patent risk while keeping the ecosystem open for hardware research.