How ChatGPT LLMs Works Excellent Graphical Illustration Video
Full tutorial link > https://www.youtube.com/watch?v=cigddCCLJRI




🤯 Unlock the Secrets of Transformer Networks: Multi-Head Self-Attention Explained Visually! 🚀 Ever wondered how Transformer networks, the powerhouse behind cutting-edge AI models like ChatGPT and BERT, truly understand language? The magic lies in a revolutionary mechanism called Multi-Head Self-Attention. This video provides a clear and intuitive visual breakdown of this crucial concept, making it accessible to everyone from beginners to seasoned machine learning enthusiasts.
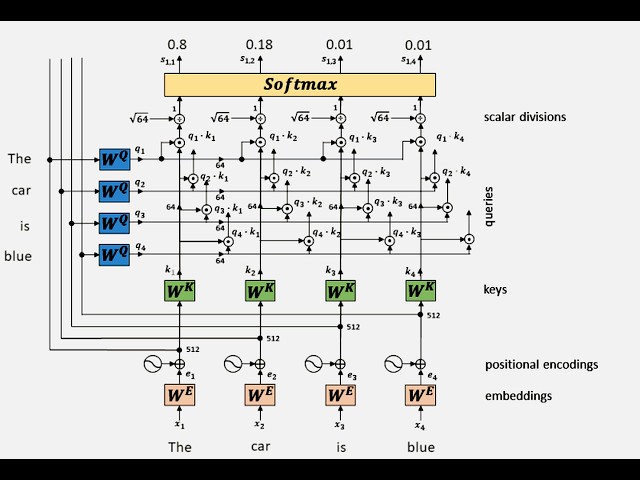
Dive deep into the inner workings of self-attention with our step-by-step animation, illustrating how a Transformer encoder processes the sentence "The car is blue". We'll unravel each stage of the process, ensuring you grasp the fundamental principles that drive these powerful models.
Here's what you'll learn in this video:
From Words to Vectors: Embeddings & Positional Encodings (00:00:00 - 00:00:20)
We begin by understanding how words are transformed into numerical representations.
Learn about word embeddings, high-dimensional vectors that capture the semantic meaning of words. In our example, "The", "car", "is", and "blue" are each converted into 512-dimensional embedding vectors (x₁, x₂, x₃, x₄).
Discover the importance of positional encodings (e₁, e₂, e₃, e₄). Since Transformers process sequences in parallel, positional encodings are added to the embeddings to inject information about the order of words in the sentence. This is crucial for understanding context!
See how these embeddings and positional encodings are combined using addition to create the initial input for the attention mechanism.
Calculating Keys, Queries, and Values (00:00:21 - 00:00:41)
Uncover the core components of self-attention: Queries (q), Keys (k), and Values (v).
Witness how each input embedding (e₁, e₂, e₃, e₄) is transformed into these three vectors using separate weight matrices:
Wᴷ (Key Weight Matrix): Projects embeddings into the Key space, generating key vectors (k₁, k₂, k₃, k₄).
W- 0xE1 -- 0xB5 -- 0x9B - (Query Weight Matrix): Projects embeddings into the Query space, generating query vectors (q₁, q₂, q₃, q₄).
W- 0xE1 -- 0xB5 -- 0x9B - (Value Weight Matrix): Projects embeddings into the Value space, generating value vectors (v₁, v₂, v₃, v₄).
Notice that these weight matrices are learned during the training process, allowing the network to focus on relevant aspects of the input.
In this example, we show a dimension reduction step: embeddings of size 512 are projected to Keys, Queries and Values of size 64, which is common in Transformer architectures for efficiency and capturing focused attention.
The Attention Score: Dot Products and Scaling (00:00:42 - 00:01:26)
Grasp the concept of attention scores, which determine how much each word should attend to every other word in the sentence.
Observe the calculation of these scores through dot products between each Query vector and all Key vectors. For example, for the first word "The" (q₁), we compute dot products with k₁, k₂, k₃, and k₄ (q₁·k₁, q₁·k₂, q₁·k₃, q₁·k₄).
Understand the importance of scaling these dot products by dividing them by the square root of the key dimension (√64 = 8 in this case). This scaling stabilizes training and prevents gradients from becoming too large.
Softmax and Attention Coefficients (00:01:27 - 00:01:39)
See how the scaled dot products are passed through a Softmax function.
Learn that Softmax converts these scores into attention coefficients (sᵢ,ⱼ), which are probabilities ranging from 0 to 1. These coefficients represent the "attention weight" assigned to each word pair.
In our example, you'll see hypothetical attention coefficients like s₁,₁=0.8, s₁,₂=0.18, s₁,₃=0.01, s₁,₄=0.01, illustrating that "The" primarily attends to itself, but also has some attention to "car".
Weighted Value Aggregation (00:01:40 - 00:02:34)
Witness how the attention coefficients are used to weigh the Value vectors.
Each value vector (vᵢ) is multiplied pointwise by its corresponding attention coefficients (sᵢ,ⱼ). For example, v₁ is multiplied by s₁,₁, s₂,₁, s₃,₁, and s₄,₁.
These weighted value vectors are then summed together to produce the contextualized embedding (zᵢ) for each word. This is where the "attention" happens – the output embedding for "The" (z₁) is now a weighted sum of all value vectors, with weights determined by the attention coefficients.
Multi-Head Attention: Parallel Attention for Richer Representations (00:02:35 - 00:03:12)
Discover the power of Multi-Head Self-Attention. Instead of just one attention mechanism, Transformers use multiple "heads" operating in parallel.
3 Song: Robin Hustin x TobiMorrow - Light It Up (feat. Jex) [NCS Release]
Music provided by NoCopyrightSounds
Free Download/Stream: http://ncs.io/LightItUp
Watch: http://youtu.be/bdE_SyHad90
4 Song: Egzod, Maestro Chives, Neoni - Royalty [NCS Release]
Free Download/Stream: http://ncs.io/Royalty